Codage du texte
Lorsqu'on parle de codage d'un texte, il y a deux aspects:
- le texte lui même, c'est-à-dire les différents caractères qui forment le texte
- la mise en forme du texte (en gras, centré, souligné...)
Représentation des caractères
Un texte est une suite de caractères: lettres majuscules, minuscules, chiffres, symboles de ponctuation, espace et caractères un peu plus spéciaux (comme %, #...).
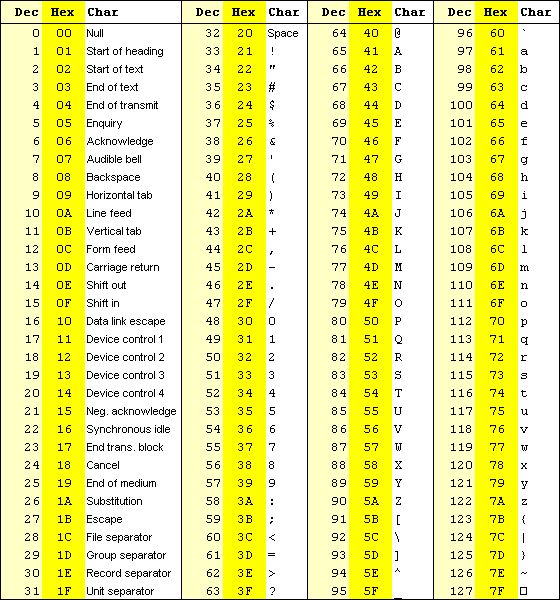
Le code ASCII (Américain Standard Code for Information Interchange, inventé par Bob Berner en 1961) code les différents caractères sur 7 bits, soit 128 possibilités. Cela suffit pour coder les 26 lettres minuscules, les 26 lettres majuscules, les 10 chiffres, l'espace et 32 symboles, soit 95 caractères proprement dits. Il reste 32 mots binaires de 7 binaires, servant à coder de la mise en page (retour à la ligne, saut de page...). Les ordinateurs fonctionnant desormais en octet, ces caractères sont en fait représentés par des mots de 8 bits dont le premier est toujours 0.
Le français utilise comme de nombreuses autres langues européennes l'alphabet latin, comportant plus de caractères que l'alphabet anglosaxon (lettres accentuées, cédille...). On a donc d'abord concu une extension de l'ASCII (en utilisant le premier bit) appelée Latin-1 contenant 191 caractères. Comme c'etait insuffisant pour les langues d'Europe de l'Est, on a proposé le latin-2. Puis devant la mondialisation des échanges d'information incluant désomais grec, chinois, russe..., il a fallu proposer un format universel: Unicode. Il recense près de 110 000 caractères et associe un nom et un numero (codé sur 32 bits) pour chacun. L'universalité a donc un coût important en terme de mémoire. C'est pour cela que ce standard ne s'est pas complètement imposé dans le monde malgré les efforts des comités de normalisation. Dans un souci d'optimisation de la mémoire, l'UTF-8 est une déclinaison de l'Unicode qui code sur 8 bits les caractères les plus fréquents et sur 16,32 ou 64 bits les autres caractères selon leur occurence.
exemple:
- Traduire le code binaire ASCII (sur 8 bits):
01000011 00100111 01100101 01110011 01110100 00100000 01100110 01100001 01100011 01101001 01101100 01100101
- Traduire en ASCII binaire: Vive ISN!
Représentation de textes enrichis
Lorsqu'on utilise un éditeur de texte (OpenOffice, Word, LateX ou HTML...) on ajoute au texte une mise en forme:
choix de la police (Courier, Times...), taille (10 points, 12 points...), forme (italique), graisse...
On peut également lui donner de la structure en le découpant en chapitres (avec des titres, des sous titres, des paragraphes...),
présentant certaines informations sous forme de listes...
Or les seules caractéristiques que l'on peut exprimer avec un code comme l'ASCII sont la casse et le découpage en paragraphe. Les traitements de texte sont les logiciels qui permettent ces mises en page plus élaborées. Ils enrichissent ces formats de manière à:
- qualifier certaines parties du texte (gras, souligné, italique...)
- structurer le texte en divisions (parties, titres, sous titres, sections, paragraphes...)
- présenter des informations sous forme de listes, de tableaux...
- faire référence à d'autres textes
- joindre des informations sur le texte (titre, Auteur, date de dréation, langue, mots clefs...). Ce sont bien des informations sur le texte et pas du texte: on les appelle des méta-données.\\
A titres d'exemple, nous nous initierons en TP au langage HTML qui sert à décrire les pages Web, qui a la particularité de permettre de créer des liens entre les textes.